| modified | Wednesday 1 January 2025 |
|---|
I don’t like how modern web applications are built. Many of the web applications are too unstable, That you can’t imagine having the system running without a team supporting it. The fact that we try to automate manual processes then the automation needs manual intervention defies the purpose. Some companies has an army of developers if they were to do the business by hand they would make a better job than the programmed system. There are many reasons for this situation. One of the reasons is the excessive use of third party dependencies.
Lets take a look on a basic modern web based system, There are several layers on software running on the machine, starting from firmware to your business logic.
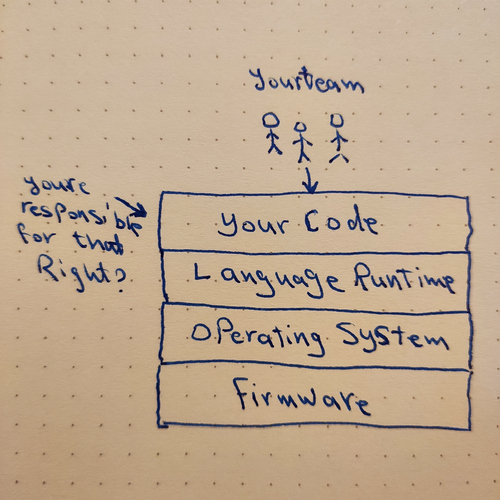
I don’t think this is very helpful to understand the gravity of the situation. There are many actors that are not considered in this picture. Layers are also missing because they are implicit in other layers. Lets expand these hidden layers and actors. It will help us understand better why that small Nodejs or RubyOnRails application we wrote isn’t just one layer in this picture.
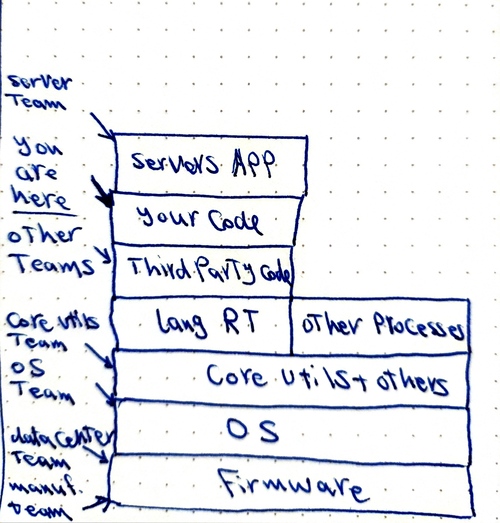
Here are the layers we added this time:
- System core utilities
- Other processes your application depends on like “memcached, Redis, MySQL, Postgres…etc”
- Third party code your application depends on an ORM, Template engine, pagination library, a library that pads your string with spaces just because.
- Server applications that sits in front of your code handling HTTP and response compression…etc.
For each of these layers there is at least one team responsible for maintaining it.
Again, We missed other layers and people in this picture. Most of the applications are using external SAAS providers for logs or monitoring or bug reporting or provide parts of the system functionality that can take more time to build by the company team. lets add them to the picture along with their teams.
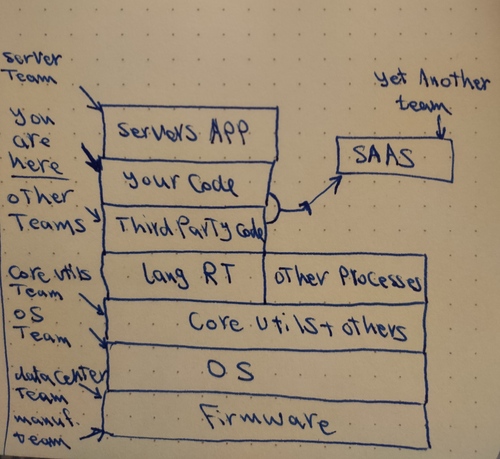
This picture is for one application, I won’t expand it to a whole system with different services and programs that is the reality of all companies. Lets stick to one application for the sake of simplicity.
So here is the first point I want to make: With every service you use you’re not just a user, This service is now part of your application, You are held responsible for it’s behavior and misbehaving. You will inherit bugs in their system. When this service team is affected by COVID-19 and get reduced to the point where they can’t fix issues you will be affected too. When They get slower your application will get slower too. When their service is down your application will experience malfunction too, Your system and theirs is now connected. So add external services integration cautiously. By adding an external system you’re putting your trust in this service team and their ability in delivering what the service is promising now and in the future. This is not an easy decision and it should be treated as such.

Now lets move to the direct dependencies of your application. If you’re using any modern programming language it’ll have a way to package code into reusable format that could be reused by other applications. one package can use code from other packages, these packages can use other packages and so on like a tree.
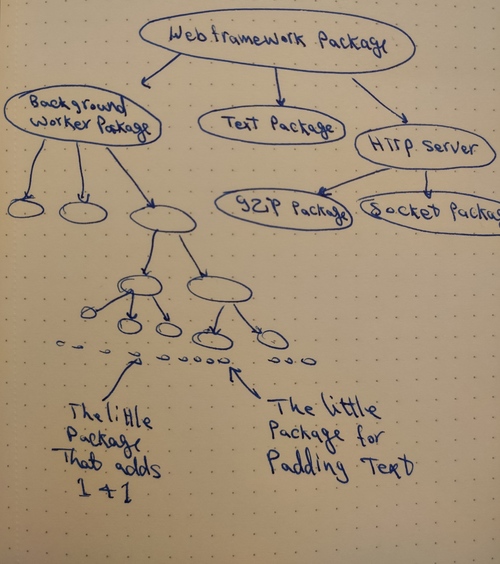
With every package in this tree we depend on the code inside this package and the team that maintains it. A freshly generated rails project depends on 74 packages for ruby and Yarn list that lists JavaScript dependencies output 3102 lines, that’s 3176 packages with teams maintaining them and bugs and new versions all the time.
This is wrong for many reasons. I will list some of them here for the sake of clarity.
- You have put your trust in at least 3176 other developers. You have never met them, never talked to them, there are no guarantee they will continue to maintain this package. There are no guarantee they won’t put code in their package to show ads in your terminal or code that steals your bitcoin wallets .
- You are not really using all of this code. When someone is writing an open source package it will suffer sooner or later from feature creeping You are probably using couple features of this package and don’t need the rest, but you wanted the banana and got the whole forest now.
- With every package update you’re inventing unnecessary work for yourself. New versions of packages are released all the time. Updating your project to get the latest bug fixes and features is usually what people do. Most of the time because of feature creeping these versions changes are not relevant to you at all, but you won’t know until you read the change log. If it’s relevant to your project you’ll need to do an update. if something is deprecated or changed you’ll need to change your code. So suddenly someone somewhere is telling you to change your code. That’s part of the control you have over your code handed over to someone you never talked to or knew.
- When your programming language has a new release you can’t update unless all of your dependencies are up to date. For ruby 2.7.0 for example some language syntax is now deprecated and shows warning when you run your project. So to fix that you either fix it in the package and open a PR with the change or wait for the maintainer to update it.
- When you encounter a bug in a dependency you will have to understand this package code, fork, branch, fix rinse and repeat. That requires a some cooperation from the library maintainer which is most of the time isn’t possible because most of the open source projects are voluntarily maintained.
- Developing new features or modifying existing features are ordre of magnitude harder. You’ll need to dig into the documentation of the dependencies looking for support for this little feature you want to add. That is if there is any documentation at all for that part of the code. Otherwise you’ll have to dig in to the library code.
This is the second point I want to make: Using external library implies that you trust the maintainer and you also inherit his decisions about using other libraries and so forth. This decision should be weighed based on the benefit of the library and how many of it’s features you’re going to use and other factors like the maturity and how responsive is the maintainer, please don’t use GitHub stars as a factor in your decision it’s misleading. And if the part you use from the library isn’t too big I recommend using the library to save some time and effort upfront but make sure you get rid of it and implement the part you need. An example of that is a pagination library like rails “Kaminari” if you’re using it to save you some time then sure. But keep on your todo list a task to remove it and implement the feature yourself. An example of libraries that’s hard to get rid of it “OpenCV” This is something that reimplementing the part you need probably will be a huge task so it can stay. You’ll need to use your best judgment to decide between these 2 sides of the spectrum.
I like to think of what I do as building an automated system, I would like this system to run by itself, keep itself clean and healthy, doesn’t need manual intervention. If the whole team disappeared out of existence I would like that system to work for a very long time without any supervision.
More code means more bugs for me to fix, by extension more code that I didn’t write means more bugs that I probably can’t solve. This is dangerous and shouldn’t be taken lightly. Extending your code with external libraries or systems can cut down effort hence the cost of development. But when this is taken lightly it backfires badly.
HN comments: https://news.ycombinator.com/item?id=24493865