Attention is all you need
Page Properties
| modified | Wednesday 12 April 2023 |
|---|
Edited: Wednesday 12 April 2023
Terms ¶
- Long short-term memory
- Attention
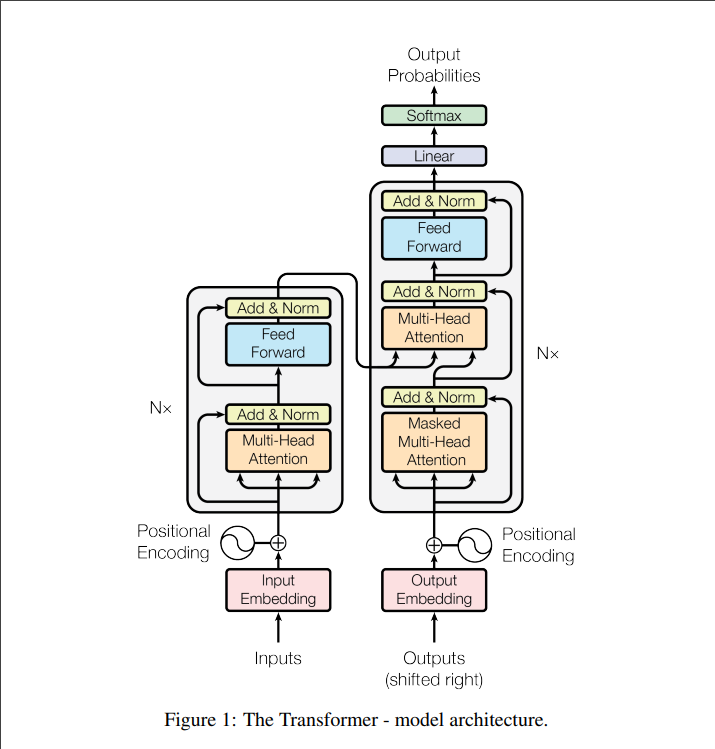
In this work we propose the Transformer, a model architecture eschewing recurrence and instead
relying entirely on an attention mechanism to draw global dependencies between input and output.
The Transformer allows for significantly more parallelization and can reach a new state of the art in
translation quality after being trained for as little as twelve hours on eight P100 GPUs. - Extended Neural GPU
Diagrams ¶